30 Nov 2022
Recent fuzz testing has uncovered a bug in capnproto-rust and capnproto-c++ that allows out-of-bounds memory to be accessed in certain situations.
If a message consumer expects data of type “list of pointers”, and if the consumer performs certain specific actions on such data, then a message producer can cause the consumer to read out-of-bounds memory. This could trigger a process crash in the consumer, or in some cases could allow exfiltration of private in-memory data.
See the advisory on the main Cap’n Proto repo for a succinct description of the exact circumstances in which the problem can arise, and for information about how to update the Cap’n Proto C++ library.
If you use the capnp Rust crate,
you are advised to update to a version that includes the fix —
currently either 0.15.2, 0.14.11, or 0.13.7.
July 2013: The initial capnproto-rust implementation copies the C++ implementation, bug and all.
February 2017: Two cargo fuzz test targets
(named
canonicalize and
test_all_types)
are added
to the capnproto-rust repo. Initial findings are reported in
a blog post.
The out-of-bounds bug is not found, due to insufficient coverage.
11 November 2022: The test_all_types fuzz test target is
expanded
to achieve additional coverage.
(later) 11 November 2022: A several-hour run of cargo fuzz -j 25 triggers an
Address Sanitizer error.
12 November 2022: The bug is diagnosed and determined to also apply to capnproto-c++. A report is sent to kenton@cloudflare.com.
The bug arises from an interaction between a core feature of Cap’n Proto (type-agnostic copying) and an optimization (list pointer munging) which failed to correctly take that feature into account.
Types of Cap’n Proto messages are defined in schema files, as described in the language reference. To be given meaning, a Cap’n Proto message must be ascribed a type.
Nevertheless, many operations on Cap’n Proto messages can proceed without reference to these high-level types. At a low level, Cap’n Proto messages have a simple self-describing structure, divided into two components: primitive data and pointers.
Primitive data is flat and opaque.
It consists of bytes that can
be interpreted as scalar values of type
UInt8, UInt16, UInt32, UInt32, UInt64,
Int8, Int16, Int32, Int32, Int64,
Float32, or Float64.
The interpretation as scalar values is
not a self-describing part of a message;
it requires the message to be ascribed
a high-level type via a schema.
Pointers introduce indirection, pointing to either structs or lists (or capabilities in the RPC system). A struct is a container with a data section holding some amount of primitive data, and a pointer section holding some number of pointers. A list is a sequence of elements, each containing some amount of primitive data and some number of pointers. For both struct and list pointers, the pointer itself describes the size of the contents, i.e. number of primitive data bytes and number of pointers.
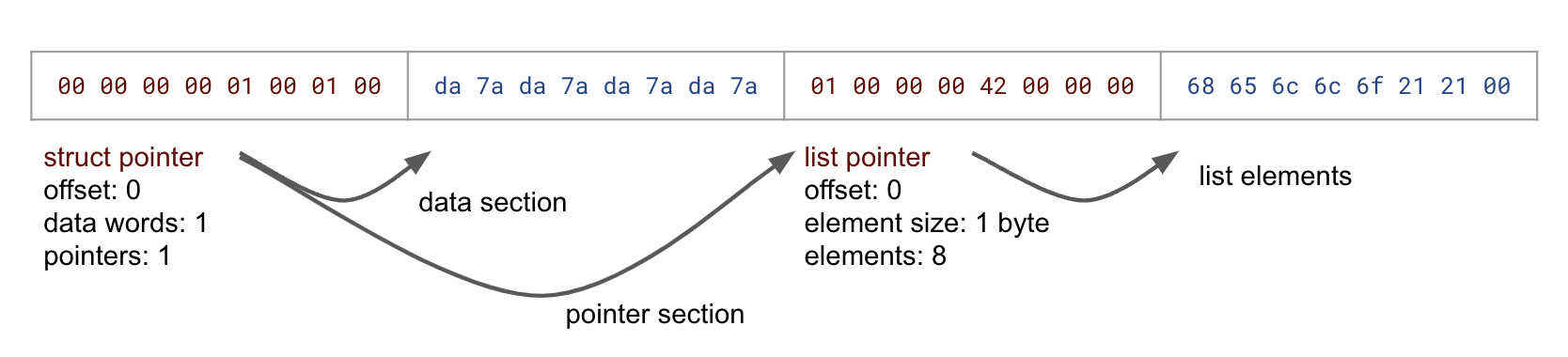
The above diagram shows the structure of an example 4-word (32-byte) message. A struct pointer points to a 1-word data section, containing 8 bytes of primitive data, and a 1-word pointer section, containing a list pointer. The list pointer points to an 8-element list of bytes (also primitive data).
This low-level structure provides enough information on its own to support traversal, copying, and even canonicalization of Cap’n Proto messages, without reference to high-level schema information.
Let’s look at some code in a concrete example where copying in particular comes into play. Consider the following schema.
struct Record {
x @0 :Int32;
y @1 :Int32;
comments @2 :Text;
}
struct Input {
record @0 :Record;
tags @1 :List(Text);
# ... plus other Input-specific fields
}
struct Output {
record @0 :Record;
tags @1 :List(Text);
# ... plus other Output-specific fields
}
Imagine a setup where Alice sends an Input to Bob,
who does some processing, and then sends
an Output to Carol.

Let’s say that part of Bob’s processing is to forward the
record and tags fields of the Input into the
corresponding record and tag fields of the Output.
The Cap’n Proto schema compiler generates Rust code for Bob including something like the following:
pub mod input {
pub struct Reader<'a> { ... }
impl <'a> Reader<'a> {
get_record(self) -> Result<record::Reader<'a>, Error> { ... }
get_tags(self)
-> Result<capnp::text_list::Reader<'a>, Error> { ... }
...
}
...
}
pub mod output {
pub struct Builder<'a> { ... }
impl <'a> Builder<'a> {
set_record(&mut self, value: record::Reader<'_>)
-> Result<(), Error> { ... }
set_tags(&mut self, value: capnp::text_list::Reader<'_>)
-> Result<(), Error> { ... }
...
}
...
}
And now Bob, to copy the record and tags fields
from the Input to the Output,
will write some lines of Rust code like this:
output.set_record(input.get_record()?)?;
output.set_tags(input.get_tags()?)?;
So far, this all may seem rather straightforward and boilerplatish,
but there’s an important thing happening behind the scenes.
Namely, the implementations of set_record()
and set_tags() delegate to type-agnostic
copying functions, which operate only on the
low-level structure of the underlying messages.
That is, even though we know the high-level
types of the values that are being copied,
we ignore that information when we actually perform the copying.
There two primary advantages to this approach:
set_struct_pointer() and set_list_pointer() functions.To elaborate on (2), suppose that the schema evolves to:
struct Record {
x @0 :Int32;
y @1 :Int32;
comments @2 :Text;
key @3 :UInt64; # new field
}
Struct Tag {
name @0 :Text;
weight @1 :Float32;
}
struct Input {
record @0 :Record;
tags @1 :List(Tag); # upgraded from List(Text)
# ... plus other Input-specific fields
}
struct Output {
record @0 :Record;
tags @1 :List(Tag); # upgraded from List(Text)
# ... plus other Output-specific fields
}
Here we’ve added a key field to Record,
and we’ve upgraded the tags field from
List(Text) to List(Tag), where Tag is
a newly-added struct.
From an encoding perspective,
these schema evolutions mean that:
Record will now have an additional 8 bytes of primitive
data in its data section.tags field will now encoded as a list of structs,
rather than a list of list of bytes.The point is that the set_struct_pointer() and set_list_pointer()
functions automatically deal with these changes,
so Bob does not need to know about the schema evolution;
his existing code already faithfully forwards the new data to Carol.
So far so good.
To understand the bug, we’ll need to dig deeper
into how capnproto-rust internally represents lists.
The text_list::Reader<'a> Rust struct returned by
the get_tags() method above is a shallow wrapper
around a Rust struct called ListReader:
#[derive(Clone, Copy)]
pub struct ListReader<'a> {
// Mediated access to the rest of the message's bytes.
arena: &'a dyn ReaderArena,
// Which segment from the arena this list lives on.
segment_id: u32,
// Handles to any capabilities in the message.
cap_table: CapTableReader,
// Pointer to the start of the first element in the list.
// (Except when "munged". See below.)
ptr: *const u8,
// Number of elements in the list.
element_count: ElementCount32,
// Number of bits per list element.
step: BitCount32,
// The size of each element of the list.
element_size: ElementSize,
// If element_size is InlineComposite, then this is the
// number of bits in each struct element's data section.
// Otherwise, it is zero.
struct_data_size: BitCount32,
// If element_size is InlineComposite, then this is the
// number of pointers in each struct element's pointer section.
// Otherwise, it is zero.
struct_pointer_count: WirePointerCount16,
// How many more pointers we are allowed to follow before
// returning an error.
nesting_limit: i32,
}
There’s a lot of bookkeeping happening here. The main idea is that we have pointer to the first element of the list, plus information about the size of each element.
To retrieve the nth element from tl: text_list::Reader<'a>,
we do tl.get(n)?, which delegates
to the following ListReader method:
impl <'a> ListReader<'a> {
pub fn get_pointer_element(self, index: ElementCount32)
-> PointerReader<'a>
{ ... }
}
The logic in this method is roughly:
start at self.ptr and take an offset of self.step / 8 * index bytes.
For a text_list::Reader<'a>, it’s usually the
case that its ListReader has element_size == Pointer
and step == 64 (i.e. one word),
so in that case, get_pointer_element(index) returns the pointer
that at an offset of 8 * index from the front of the list.
But what happens if
the underlying list is actually a struct list
(i.e. element_size == InlineComposite)?
As we saw above, that can happen as a consequence of protocol
evolution, if Alice constructs a List(Tag) but Bob still
expects to read it as a List(Text).
To deal with that case, we need to also take into account
self.struct_data_size. The pointer that we want
will be the first pointer in the pointer section of the struct,
but there may be a nonempty data section that we need to skip first.
So the logic in get_pointer_element() needs to be:
start at self.ptr and take an offset of
self.step / 8 * index + self.struct_data_size / 8 bytes.
And here we might be tempted to make an optimization.
Notice that the same self.struct_data_size / 8 term
gets added on every call of get_pointer_element().
What if we added that value just once, when we first
constructed the ListReader? Then maybe we could eliminate
some instructions and squeeze out a few more bits of performance.
The original Cap’n Proto implementation included this optimization,
where ListReader.ptr would be “munged” by an offset
corresponding to the struct data size.
As long as all access to the list
goes through the get_pointer_element() method,
the optimization works without any problems.
Type-agnostic copying, however, does not go through that method.
We hit trouble when we pass a ListReader with
such a munged pointer into the set_list_pointer() function
described in the previous section.
That function has no way to know where a list pointer has been munged or not,
and expects ListReader.ptr to always point to the start
of the first element of the list.
Therefore, when it receives a munged pointer,
it will start reading from it at an offset of struct_data_size
past where it should.
If the end of the message segment is within
that offset, then set_list_pointer() can read out-of-bounds data,
from beyond the end of the message.
The bug is fixed by commit e7ee0ef892c354b0390ed6e38d3ca634308897c5, which eliminates the bad optimization.