News
capnproto-java alpha release with benchmarks
I’m happy to announce that capnproto-java is now a mostly complete implementation of the Cap’n Proto serialization protocol. It supports all of the data features of the Cap’n Proto schema language, including constants, default values, and arbitrarily nested list types. Moreover, the runtime and the generated code consist entirely of platform-independent, safe Java code.
In the spirit of previous announcements about the Rust and OCaml implementations, I’ve made some informal measurements with the usual toy benchmark suite. The results show the Java implementation performing at worst 3x slower than the C++ and Rust implementations, and at best about 2x slower. I find these results promising, considering how difficult it can be to avoid heap allocations and redundant bounds-checking on the JVM.
I ran each of the three benchmark cases in five modes. In the “object” mode, the data is passed in-process without any copying. In the “bytes” mode, the data is written to a flat array and then re-read in-process. In the “pipe” mode, the data is passed as a byte stream between separate processes. In the “packed” sub-modes, a compression scheme is applied to the bytes before they are passed.
To give the JVM a chance to amortize the cost of just-in-time compilation, I ran the benchmarks for 10x more iterations than in the previous Rust vs. C++ benchmarks.
Here are the results.
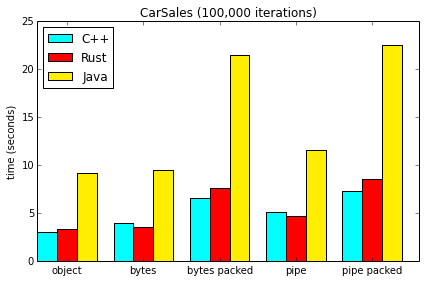
The CarSales case does a lot of
iteration through lists of structs.
One way to improve Java’s performance here
might be to implement list iterators
that update in-place, so that we don’t
need to allocate a new StructReader for each
member of a list.
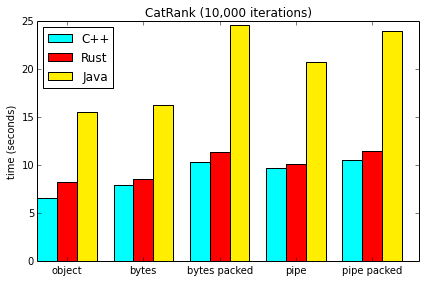
The CatRank case emphasizes string processing. One big difficulty faced by Java here is that it uses UTF-16 encoding, while Cap’n Proto uses UTF-8; translating between the two requires significant copying of memory.
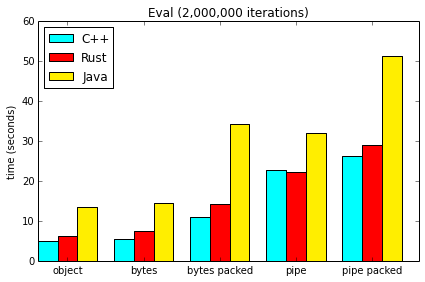
The Eval case seems to confirm that packing costs proportionally more for Java than for the other implementations. There are almost certainly still some optimizations we could apply to that part of the Java implementation, but we may be fundamentally limited by the fact that Java bounds-checks every array access.